
SpringCloud简介
微服务是目前比较火热的概念,而SpringCloud又是实现微服务的框架中最热门之一。
严格来讲,SpringCloud是一个生态而不是一个框架,它由很多框架组件组合而成,而整个生态又是基于SpringBoot的基础上建立。
所以,跟SpringBoot一样给人的感觉就是方便、快捷、易用和强劲,非常方便地进行云端部署和容器化,总之好东西全占足了。
Eureka简介
"Eureka"是由于发现某种事物,尤其是问题答案而高兴。" Eureka, I got it!! "
跟它的字面意思很相近,在SpringCloud的生态圈里它担认【服务发现】 和【服务注册管理】。
那它跟Zookeeper 有什么异同呢?
- 相同的是,Zookeeper也是负责这类事务。
- 不同的是,Zookeeper 初衷并不是要做“服务注册中心”的,它所要解决的问题是分布式存储的一致性,所以高可用并不是它首要关心的问题,因此,当它Leader丢失后重新选举Leader是一件非常耗时的操作,最主要的是在这期间整个Zk集群是停止响应的;Eureka 是专门为“服务发现注册”而生的,所以,它首要关注的是高可用性,至于服务状态的一致性其实并不保证的,“服务发现注册”对于一致性并不是很敏感,假如一个Client获取到的服务状态有延时那会有多大的影响呢?跟长时间无响应比还是九牛一毛的,而且基本上都有策略进行弥补。
Eureka2.0 Vs Eureka1.0
虽然,V2.0还在开发,但是它较V1.0的重大优化项早已放出,主要如下:
- 增加“服务关注”功能,V1.0中Client端没有权利选择自己关注的服务或者IP地址,所有的注册内容照单全收,譬如一个老师的Service,它可能只需要关心学生Service,对它来说警察Service跟它没有任何关系,这样的优化可以让服务更新减少很大的流量。
- 将poll的模式改为push,因为poll模式最大的缺点就是 “没改变时白拉,改变了有迟拉”,push的方式是一种比较自然的事件通知的方式。
- V1.0时使用的是广播全量数据复制的方式,它要求将所有状态数据和心跳都同步到配置的每个Peer上,这样每个Peer上都承担了相同的所有流量,对带宽的压力还是非常大的。V2.0开始将分为写集群和读集群,根据Client的数量和流量来动态扩展读集群(下面详细介绍)。
Eureka2.0
1. 架构
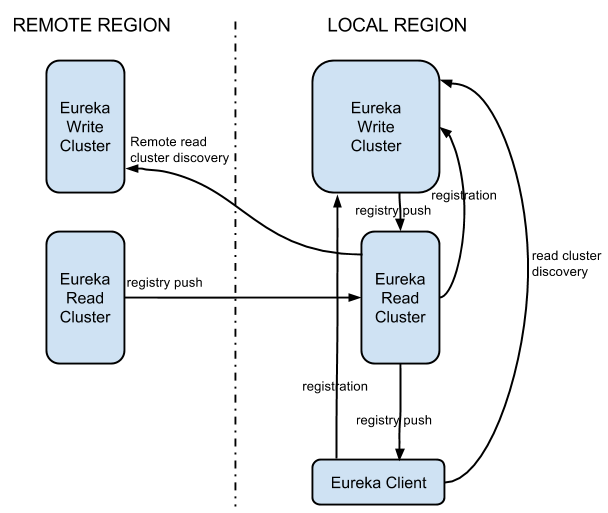
正如上面所述,2.0将根据功能分为读、写集群,读集群充当了一个“缓存层”的作用,写集群跟之前功能差不多,不同的是它负责将状态数据的变更推送给读集群而不是Client,并且它还存储了读集群的地址信息,所以当Client扩充时只需要动态扩充读集群就行了,而且一台读集群中的实例能服务很多Client,对于写集群无疑减少一个数量级的信息推送。多个集群之间可以做相互调用,地位跟Client一样。
2. Client注册
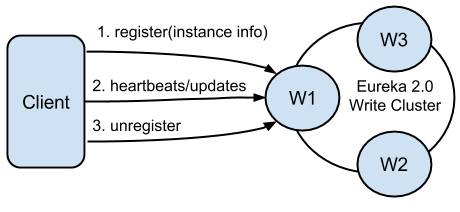
一个客户端Client可以连接多个服务实例, 每个实例维持独立的连接和心跳。
3. 库发现
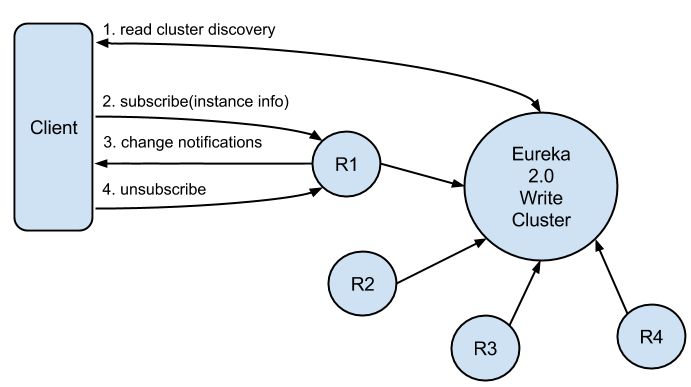
当Client订阅完关心的服务后,后续的信息更新由读集群负责。
总结
总体来说V2.0做了翻天覆地的变化(架构方面,API应该不变),很容易就可以推测带的性能优化是显著的。
对于具体的实现和优化细节由于还没有看源码,所以描述不是很到位,希望后续能够补上,也欢迎各位留言补充和指正,不甚感谢!
参考